In just one short month, LECOLE has generated an astounding 10,000+ practice questions. But quantity is only half the story. Driven by your invaluable feedback and usage patterns, we’ve continuously refined our AI models, leading to the birth of our groundbreaking SAT Generation Bundle V2.0.
Introducing the 13-Model Powerhouse
The enhanced SAT Generation Bundle V2.0 isn’t powered by a single AI model, but an ensemble of 13 distinct generative models. Each model is a specialist, trained and fine-tuned on specific facets of the Digital SAT, ensuring comprehensive coverage and unparalleled accuracy in question generation.
Why 13 Models?
const MODELS = {
Inferences: '2.0',
'Central Ideas and Details': '2.0',
'Command of Evidence': {
text: '2.0',
table: '2.0',
graph: '2.0'
},
'Words in Context': {
text: '2.0',
fill: '2.0'
},
'Text Structure and Purpose': '2.0',
'Cross-Text Connections': '2.0',
'Rhetorical Synthesis': '2.0',
Transitions: '2.0',
Boundaries: '2.0',
'Form, Structure, and Sense': '2.0'
};Instead of relying on a single, monolithic AI model that could be prone to hallucinations and overfitting, we’ve divided the Digital SAT domain into 13 specialized models. This approach ensures that each model can focus on mastering a specific aspect of the exam, leading to better accuracy and a deeper level of expertise in question generation. By distributing the workload across multiple models, we also mitigate the risks associated with overfitting, ensuring that our AI remains adaptable and generalizes well to new, unseen SAT content.
How We Achieved This Breakthrough
The impressive advancements in SAT Generation Bundle V2.0 weren’t achieved overnight. They are the result of a data-driven process that combines cutting-edge AI techniques with insights gleaned from real student interactions.
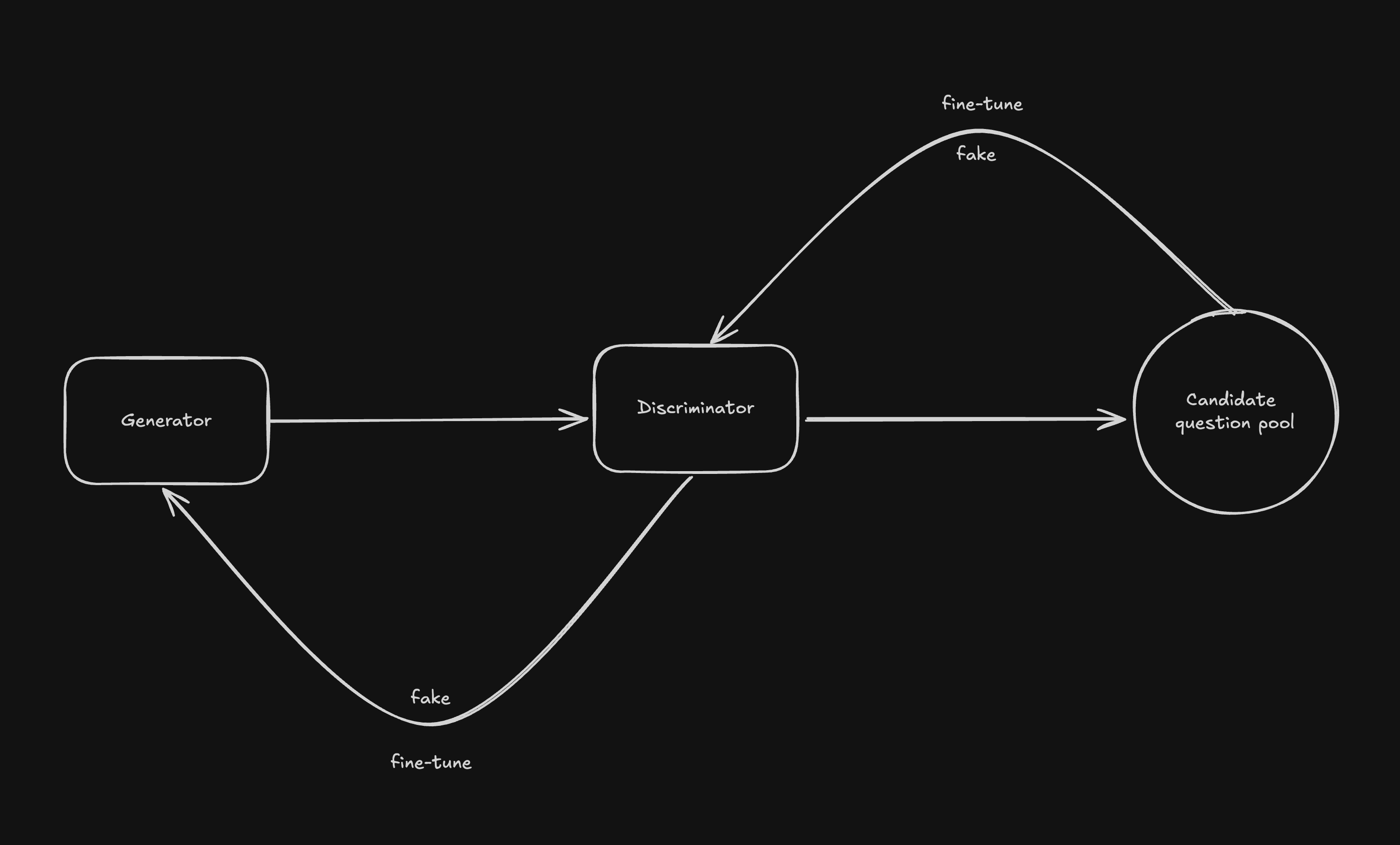
1. Imposter & Detective
Just like the roles from that of a famous video game, Our model took inspiration from GAN (Generative Adversarial Network) to detect and label each question sample.
-
The Imposter (Generator): This model is tasked with creating convincing SAT-style questions. It’s constantly striving to outsmart its opponent, crafting questions that are increasingly sophisticated and challenging.
-
The Detective (Discriminator): This model carefully scrutinizes each question generated by the Imposter. Its mission is to distinguish between the “real” (authentic SAT questions) and the “fake” (AI-generated questions).
This continuous interplay pushes both models to constantly elevate their performance. It’s akin to a rigorous training regimen, where each model learns from the other, ultimately resulting in practice questions that are virtually indistinguishable from those found on the actual SAT.
We’re committed to providing a fair and unbiased learning experience. By leveraging AI and data-driven insights, we’ve minimized the unintentional biases that can sometimes creep into traditional question banks. With LECOLE, you can be confident that you’re practicing with questions that genuinely reflect the Digital SAT. No curveballs or unexpected surprises, just straightforward, high-quality practice to help you achieve your best score.
2. Next-level prompt engineering
Beyond the Imposter/Detective dynamic, we wanted to push the boundaries of our models’ question-generating capabilities. To achieve this, we looked to G-Eval (Liu et al., 2023), a technique for evaluating the quality of natural language generation (NLG). G-Eval’s core principle is to assess the model’s ability to produce text that aligns with human expectations and standards. By applying this philosophy to our SAT question generation process, we aimed to create questions that not only look like real SAT questions but also feel like them, capturing the nuances and complexities that students and teachers encounter on the actual exam.
We also incorporated “Chain of Thoughts” prompting, a method where the AI is given step-by-step instructions rather than a simple command. This technique helps the model break down complex tasks into manageable components, encouraging it to engage in a more deliberate and logical reasoning process. Think of it as providing a roadmap for the AI, guiding it through the essential considerations when crafting an SAT question, such as:
- Determine if the question is related to the prompt and skills.
- Check again the options.
- Score from a scale from 1 to 5, anything below 4 is fake.
By combining G-Eval’s focus on human-like output with the structured guidance of Chain of Thoughts prompting, we’ve been able to refine our models to a remarkable degree. The questions they generate aren’t just facsimiles of the real thing; they embody the same level of rigor, critical thinking, and problem-solving skills that the SAT demands.
3. More consistent result
By leveraging the enhanced structured prompting capabilities offered by OpenAI’s GPT-4 models, we have achieved a substantial reduction in the incidence of disqualified or incorrectly formatted questions generated by our system. This optimization directly translates to a marked improvement in question generation speed, thereby ensuring a more efficient and streamlined user experience.
The Proof is in the Results
LECOLE’s latest advancements have revolutionized SAT prep, delivering a powerful combination of improved accuracy, speed, and affordability. Experience a remarkable 1.5x increase in question accuracy, ensuring your practice sessions are as close to the real Digital SAT as possible. Additionally, our optimized platform now boasts a 1.3x faster question generation speed, minimizing wait times and maximizing your learning efficiency. Best of all, these improvements come at twice the cost-effectiveness, making top-tier SAT prep accessible to everyone.